Kounta POS is now Lightspeed!
Loved by over 10,000 venues across Australia and New Zealand and supported by the same team of passionate hospitality experts, our industry's most trusted POS is now powered by Lightspeed.

Looking for a point of sale system?
Lightspeed (formerly Kounta) caters to all types of venues: from small espresso bars to multi-venue restaurants. Offering flexible monthly plans that suit different business needs, Lightspeed lets you build a POS that’s right for you and ready for what the future holds. So when your business grows, so does your point of sale.
Taking orders with Lightspeed
Lightspeed (formerly Kounta) equips you with all the flexibility so that you can provide your customers with the same – no matter how they choose to place their order.
- Orders at counter: cut wait times with a fast and precise POS interface
- Orders from floor staff: minimise mistakes by sending orders straight to print
- Orders from QR menu: give customers the option to order (& pay) from their smartphone with a QR menu integrated to Lightspeed POS
- Orders for delivery: sync delivery with Lightspeed so they fit seamlessly into existing workflows

Payments with Lightspeed
As customer behaviour changes so do payments with Kounta. With Lightspeed point of sale, you can:
- Accept all payment types: including Apple Pay & Google Pay
- Let customers split bills: by amounts or by items
- Reduce errors: no double keying of payments – straight from POS to EFTPOS
- Integrate with your accounting software: for painless reconciliation

Inventory management
Lightspeed POS goes beyond front of house. With inventory management features, you can manage supplies, costs, and the quality of your dishes.
- Manage supplies: stock on hand, deliveries due & planned prep from one dashboard
- Order to par: in seconds, with automated updates to your inventory
- Track COGs: and maintain consistency of dishes with a built-in recipe costing tool
- Track & reduce wastage: and control costs

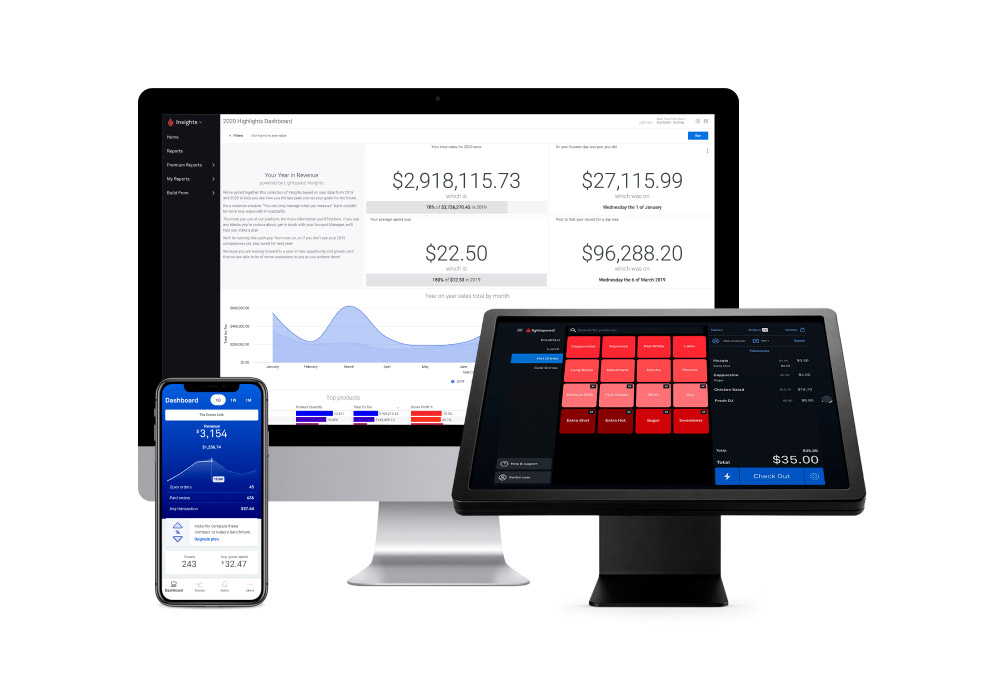
Reporting with Lightspeed
We want to empower all Lightspeed users with data. So no matter what plan you’re on, you’ll have access to our live Insights app so you can see real-time sales no matter where you are. When you’re ready to take your analytics to the next level, simply upgrade your Insights plan and you’ll also have access to:
- Custom reports: products, staff performance, weekly trends & more
- Trends: compare current performance to your benchmarks
- Alerts: instant notifications of key events in your business
- Schedule reports: automated & easy-to-read visualisations of your data
Business tools integration
Lightspeed partners with the best in the business so that you can manage your entire business from one place – with no additional costs to integrate. With Lightspeed POS you can integrate:
- Accounting: Xero, MYOB, QuickBooks
- Ordering & delivery: Deliveroo, Uber Eats, DoorDash, me&u, Mr Yum & more
- Marketing & loyalty: Liven, Marsello, Loke
- Employee management: Deputy, Tanda

Lightspeed support
Hospitality’s most loved and passionate service team, no Lightspeed experience is complete without our service team. With Lightspeed POS, you’ll get:
- One-on-one onboarding: and easy POS set-up
- Dedicated account manager: to discuss & plan your business success
- Guides & support: fully stacked library at your fingertips
- Unlimited 24/7 support: hospitality never stops, and neither does our team







Visit our hardware store
Bring your own setup or put together a tailor-made bundle in our POS hardware store. Our top-quality hardware is tailored to the demands of hospitality and can handle the hustle of your busiest shifts.

The Lightspeed story
Almost everyone at Lightspeed is from hospitality – most of us have either worked in venues before or ran our own. Along with the rewards, we understand the frustrations. And so does our platform. Lightspeed POS is engineered to solve real-life problems with features inspired by hands-on industry experience.
FAQs
Are Kounta and Lightspeed the same company?
Yes, Kounta is now a part of Lightspeed. Our commitment to the hospitality community remains unchanged, as does our local team of passionate hospitality experts.
Will there be any changes to Kounta’s pricing?
No, Kounta becoming a part of Lightspeed will not impact the pricing of our POS plans. In fact, with more resources, we’ll be able to roll out features at an even faster pace.
Will I still be able to integrate Lightspeed POS with my business tools?
Yes. There are no changes to our integrations so you can integrate Lightspeed POS with your favourite business tools (Xero, MYOB, etc.) at no additional costs
Find out what Lightspeed can do for your business
Fill in your contact details and one of our experts will be in touch shortly.